A ANOVA (Análise de Variância) de uma via é um teste estatístico utilizado para comparar as médias de três ou mais grupos independentes, determinando se há evidências de que pelo menos uma das médias difere significativamente das demais. É uma extensão do teste t para amostras independentes.
Definição das hipóteses do estudo
H0: as médias de todos os grupos são iguais;
H1: pelo menos uma média é diferente.
Pressupostos da ANOVA One-Way
Normalidade dos resíduos.
Homogeneidade de variâncias (homocedasticidade).
Independência das observações.
Exemplo prático com o dataset PlantGrowth
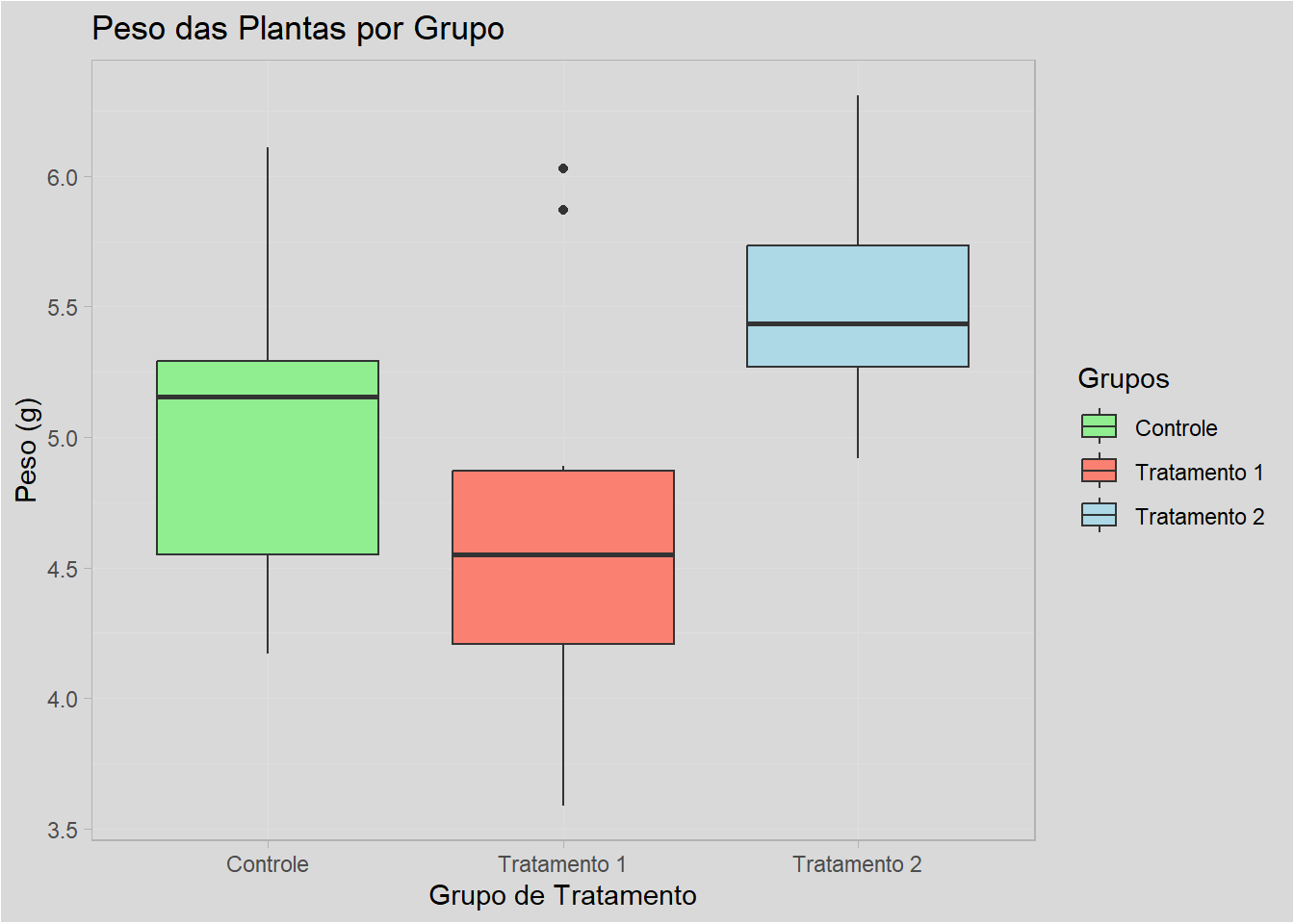
Antes de realizar o teste da ANOVA One-Way, vamos fazer algumas análises descritivas para visualizar o conjunto de dados, os valores das estatísticas de resumo, a estrutura dos dados para entender quais variáveis numéricas e fatoriais e um gráfico para avaliar os grupos de estudo.
# Carregar pacoteslibrary(tidyverse) # Manipulação e visualização de dadoslibrary(viridis) # Carregar dadosdata(PlantGrowth)head(PlantGrowth)
$ctrl
Shapiro-Wilk normality test
data: X[[i]]
W = 0.95668, p-value = 0.7475
$trt1
Shapiro-Wilk normality test
data: X[[i]]
W = 0.93041, p-value = 0.4519
$trt2
Shapiro-Wilk normality test
data: X[[i]]
W = 0.94101, p-value = 0.5643
2. Homogeneidade de Variâncias (teste de Levene):
car::leveneTest(weight ~ group, data = PlantGrowth)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 2 1.1192 0.3412
27
Você também pode verificar a homogeneidade das variâncias usando o teste de Bartlett:
bartlett.test(weight ~ group, data = PlantGrowth)
Bartlett test of homogeneity of variances
data: weight by group
Bartlett's K-squared = 2.8786, df = 2, p-value = 0.2371
Realizando o teste da ANOVA One-Way
Primeiro, é necessário criar um modelo da anova usando a função aov() do teste. Depois, verificar os valores do teste estatístico usando a função summary().
# Criando o modelo:modelo_anova <-aov(weight ~ group, data = PlantGrowth)# Resumo do teste:summary(modelo_anova)
Df Sum Sq Mean Sq F value Pr(>F)
group 2 3.766 1.8832 4.846 0.0159 *
Residuals 27 10.492 0.3886
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Teste Post-Hoc (se a ANOVA for significativa)
Esse teste é usado para verificar diferenças estatísticas entre os grupos par a par.
TukeyHSD(modelo_anova)
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = weight ~ group, data = PlantGrowth)
$group
diff lwr upr p adj
trt1-ctrl -0.371 -1.0622161 0.3202161 0.3908711
trt2-ctrl 0.494 -0.1972161 1.1852161 0.1979960
trt2-trt1 0.865 0.1737839 1.5562161 0.0120064
Também é possível realizar o teste das diferenças par a par entre os grupos usando o pacote emmeans.
emmeans::emmeans(modelo_anova, pairwise ~ group)
$emmeans
group emmean SE df lower.CL upper.CL
ctrl 5.03 0.197 27 4.63 5.44
trt1 4.66 0.197 27 4.26 5.07
trt2 5.53 0.197 27 5.12 5.93
Confidence level used: 0.95
$contrasts
contrast estimate SE df t.ratio p.value
ctrl - trt1 0.371 0.279 27 1.331 0.3909
ctrl - trt2 -0.494 0.279 27 -1.772 0.1980
trt1 - trt2 -0.865 0.279 27 -3.103 0.0120
P value adjustment: tukey method for comparing a family of 3 estimates
Interpretação dos resultados
Primeiro, nós verificamos que os dados atendem aos pressupostos da ANOVA One-Way, devido à normalidade dos resíduos (p > 0,05) aplicado por meio do teste de Shapiro-Wilk. Também, verificados que ocorre homogeneidade das variâncias (p > 0,05) com o teste de Levene e Bartlett.
Após aplicar o teste da ANOVA, verificamos que o valor de p foi maior que 0,05, indicando que existe diferenças entre os grupos tratamento e controle.
Como ocorreu diferenças entre os grupos, foi necessário aplicar o teste Post-Hoc que apresentou diferenças entre os grupos do tratamento 1 e tratamento 2.
O gráfico mostrou que no tratamento 2 as plantas apresentaram maior peso em gramas comparado ao tratamento 1, que apesar dos outliers, não mostrou medianas e médias similares. Além disso, foi verificado que as plantas do controle apresentaram maior peso do que as plantas do tratamento 1.
Conclusão
A ANOVA one-way é uma ferramenta poderosa para comparar médias entre grupos. Neste exemplo, vimos como aplicá-la no R, verificar seus pressupostos e interpretar os resultados. Lembre-se de que os pressupostos devem ser atendidos para que a análise seja válida!
Dica: Para dados não paramétricos e que não atendem aos pressupostos da análise, considere o teste de Kruskal-Wallis (kruskal.test()).